
When I see people, and particularly conservatives, discussing why one poll is better than another, I see the sample pool frequently cited as a reason for favoring one or another. Specifically, some poll watchers insist that any poll not filtered for likely voters, instead of just registered voters or even adults, is not useful in a political context.
The dirty secret is that not all likely voters are created equal. Every pollster has his own secret sauce, and we have to be careful when trusting that kind of filtering. It might not be what we expect.
The controversy over the Daily Kos/Research 2000 polls is illustrative of this fact. Steven Shepard of Hotline On Call, along with Patterico, are claiming that these polls are undercounting voters 60 years old and above.
I’m not especially troubled by this. As long as you’re taking genuine random samples within your modeled set of likely voters, then one model of likely voters is as legitimate as another in my view.
That’s not to say they’re all equally correct. No, of course there is only one 100% correct description of likely voters, and that’s found out in November when we find out who the actual voters are. The closer to that result that a model gets, the better it is. This is objective science, not art as Markos Moulitsas insists.
Time will tell how right Research 2000 is about the voter pool for the 2010 elections. Shepard’s studies of the 2009 elections and the 2010 special elections we’ve seen are interesting, but I find a small number of races to be inconclusive. November 2010 will give us many more data points and a clear answer to the question.


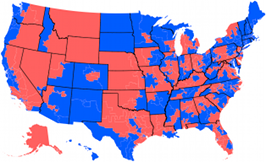 House of Representatives Swingometer
House of Representatives Swingometer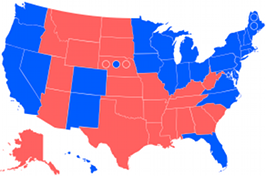 Electoral College Swingometer
Electoral College Swingometer
Comments
No Responses to “Not all Likely Voters are created equal”